What is krkn-ai?
Krkn-AI lets you automatically run Chaos scenarios and discover the most effective experiments to evaluate your system’s resilience.
How does it work?
Krkn-AI leverages evolutionary algorithms to generate experiments based on Krkn scenarios. By using user-defined objectives such as SLOs and application health checks, it can identify the critical experiments that impact the cluster.
- Generate a Krkn-AI config file using discover. Running this command will generate a YAML file that is pre-populated with cluster component information and basic setup.
- The config file can be further customized to suit your requirements for Krkn-AI testing.
- Start Krkn-AI testing:
- The evolutionary algorithm will use the cluster components specified in the config file as possible inputs required to run the Chaos scenarios.
- User-defined SLOs and application health check feedback are taken into account to guide the algorithm.
- Analyze results, evaluate the impact of different Chaos scenarios on application liveness and their fitness scores.
Getting Started
Follow the installation steps to set up the Krkn-AI CLI.
1 - Getting Started
How to deploy sample microservice and run Krkn-AI test
Getting Started with Krkn-AI
This documentation details how to deploy a sample microservice application on Kubernetes Cluster and run Krkn-AI test.
Prerequisites
- Follow this guide to install Krkn-AI CLI.
- Krkn-AI uses Thanos Querier to fetch SLO metrics by PromQL. You can easily install it by setting up prometheus-operator in your cluster.
Deploy Sample Microservice
For demonstration purpose, we will deploy a sample microservice called robot-shop on the cluster:
# Change to Krkn-AI project directory
cd krkn-ai/
# Namespace where to deploy the microservice application
export DEMO_NAMESPACE=robot-shop
# Whether the K8s cluster is an OpenShift cluster
export IS_OPENSHIFT=true
./scripts/setup-demo-microservice.sh
# Set context to the demo namespace
oc config set-context --current --namespace=$DEMO_NAMESPACE
# If you are using kubectl:
# kubectl config set-context --current --namespace=$DEMO_NAMESPACE
# Check whether pods are running
oc get pods
We will deploy a NGINX reverse proxy and a LoadBalancer service in the cluster to expose the routes for some of the pods.
# Setup NGINX reverse proxy for external access
./scripts/setup-nginx.sh
# Check nginx pod
oc get pods -l app=nginx-proxy
# Test application endpoints
./scripts/test-nginx-routes.sh
export HOST="http://$(kubectl get service rs -o json | jq -r '.status.loadBalancer.ingress[0].hostname')"
Note
If your cluster uses Ingress or custom annotation to expose the services, make sure to follow those steps.📝 Generate Configuration
Krkn-AI uses YAML configuration files to define experiments. You can generate a sample config file dynamically by running Krkn-AI discover command.
# Discover components in cluster to generate the config
$ uv run krkn_ai discover -k ./tmp/kubeconfig.yaml \
-n "robot-shop" \
-pl "service" \
-nl "kubernetes.io/hostname" \
-o ./tmp/krkn-ai.yaml \
--skip-pod-name "nginx-proxy.*"
Discover command generates a yaml file as an output that contains the initial boilerplate for testing. You can modify this file to include custom SLO definitions, cluster components and configure algorithm settings as per your testing use-case.
Running Krkn-AI
Once your test configuration is set, you can start Krkn-AI testing using the run command. This command initializes a random population sample containing Chaos Experiments based on the Krkn-AI configuration, then starts the evolutionary algorithm to run the experiments, gather feedback, and continue evolving existing scenarios until the total number of generations defined in the config is met.
# Configure Prometheus
# (Optional) In OpenShift cluster, the framework will automatically look for thanos querier in openshift-monitoring namespace.
export PROMETHEUS_URL='https://Thanos-Querier-url'
export PROMETHEUS_TOKEN='enter-access-token'
# Start Krkn-AI test
uv run krkn_ai run -vv -c ./krkn-ai.yaml -o ./tmp/results/ -p HOST=$HOST
Understanding the Results
In the ./tmp/results directory, you will find the results from testing. The final results contain information about each scenario, their fitness evaluation scores, reports, and graphs, which you can use to further investigate.
.
└── results/
├── reports/
│ ├── best_scenarios.yaml
│ ├── health_check_report.csv
│ └── graphs/
│ ├── best_generation.png
│ ├── scenario_1.png
│ ├── scenario_2.png
│ └── ...
├── yaml/
│ ├── generation_0/
│ │ ├── scenario_1.yaml
│ │ ├── scenario_2.yaml
│ │ └── ...
│ └── generation_1/
│ └── ...
├── log/
│ ├── scenario_1.log
│ ├── scenario_2.log
│ └── ...
└── krkn-ai.yaml
Reports Directory:
health_check_report.csv: Summary of application health checks containing details about the scenario, component, failure status and latency.best_scenarios.yaml: YAML file containing information about best scenario identified in each generation.best_generation.png: Visualization of best fitness score found in each generation.scenario_<ids>.png: Visualization of response time line plot for health checks and heatmap for success and failures.
YAML:
scenario_<id>.yaml: YAML file detailing about the Chaos scenario executed which includes the krknctl command, fitness scores, health check metrices, etc. These files are organised under each generation folder.
Log:
scenario_<id>.log: Logs captured from krknctl scenario.
2 - Cluster Discovery
Automatically discover cluster components for Krkn-AI testing.
Krkn-AI uses a genetic algorithm to generate Chaos scenarios. These scenarios require information about the components available in the cluster, which is obtained from the cluster_components YAML field of the Krkn-AI configuration.
CLI Usage
$ uv run krkn_ai discover --help
Usage: krkn_ai discover [OPTIONS]
Discover components for Krkn-AI tests
Options:
-k, --kubeconfig TEXT Path to cluster kubeconfig file.
-o, --output TEXT Path to save config file.
-n, --namespace TEXT Namespace(s) to discover components in. Supports
Regex and comma separated values.
-pl, --pod-label TEXT Pod Label Keys(s) to filter. Supports Regex and
comma separated values.
-nl, --node-label TEXT Node Label Keys(s) to filter. Supports Regex and
comma separated values.
-v, --verbose Increase verbosity of output.
--skip-pod-name TEXT Pod name to skip. Supports comma separated values
with regex.
--help Show this message and exit.
Example
The example below filters cluster components from namespaces that match the patterns robot-.* and etcd. In addition to namespaces, we also provide filters for pod labels and node labels. This allows us to narrow down the necessary components to consider when running a Krkn-AI test.
uv run krkn_ai discover -k ./tmp/kubeconfig.yaml \
-n "robot-.*,etcd" \
-pl "service,env" \
-nl "disktype" \
-o ./krkn-ai.yaml
The above command generates a config file that contains the basic setup to help you get started. You can customize the parameters as described in the configs documentation. If you want to exclude any cluster components—such as a pod, node, or namespace—from being considered for Krkn-AI testing, simply remove them from the cluster_components YAML field.
# Path to your kubeconfig file
kubeconfig_file_path: "./path/to/kubeconfig.yaml"
# Genetic algorithm parameters
generations: 5
population_size: 10
composition_rate: 0.3
population_injection_rate: 0.1
scenario_mutation_rate: 0.6
# Duration to wait before running next scenario (seconds)
wait_duration: 30
# Specify how result filenames are formatted
output:
result_name_fmt: "scenario_%s.yaml"
graph_name_fmt: "scenario_%s.png"
log_name_fmt: "scenario_%s.log"
# Fitness function configuration for defining SLO
# In the below example, we use Total Restarts in "robot-shop" namespace as the SLO
fitness_function:
query: 'sum(kube_pod_container_status_restarts_total{namespace="robot-shop"})'
type: point
include_krkn_failure: true
# Chaos scenarios to consider during testing
scenario:
pod-scenarios:
enable: true
application-outages:
enable: true
container-scenarios:
enable: false
node-cpu-hog:
enable: false
node-memory-hog:
enable: false
# Cluster components to consider for Krkn-AI testing
cluster_components:
namespaces:
- name: robot-shop
pods:
- containers:
- name: cart
labels:
service: cart
env: dev
name: cart-7cd6c77dbf-j4gsv
- containers:
- name: catalogue
labels:
service: catalogue
env: dev
name: catalogue-94df6b9b-pjgsr
services:
- labels:
app.kubernetes.io/managed-by: Helm
name: cart
ports:
- port: 8080
protocol: TCP
target_port: 8080
- labels:
app.kubernetes.io/managed-by: Helm
service: catalogue
name: catalogue
ports:
- port: 8080
protocol: TCP
target_port: 8080
- name: etcd
pods:
- containers:
- name: etcd
labels:
service: etcd
name: etcd-0
- containers:
- name: etcd
labels:
service: etcd
name: etcd-1
nodes:
- labels:
kubernetes.io/hostname: node-1
disktype: SSD
name: node-1
taints: []
- labels:
kubernetes.io/hostname: node-2
disktype: HDD
name: node-2
taints: []
3 - Run Krkn-AI
Execute automated resilience and chaos testing using the Krkn-AI run command.
The run command executes automated resilience and chaos testing using Krkn-AI. It initializes a random population samples containing Chaos Experiments based on your Krkn-AI configuration file, then starts the evolutionary algorithm to run the experiments, gather feedback, and continue evolving existing scenarios until stopping criteria is met.
CLI Usage
$ uv run krkn_ai run --help
Usage: krkn_ai run [OPTIONS]
Run Krkn-AI tests
Options:
-c, --config TEXT Path to Krkn-AI config file.
-o, --output TEXT Directory to save results.
-f, --format [json|yaml] Format of the output file. [default: yaml]
-r, --runner-type [krknctl|krknhub] Type of chaos engine to use.
-p, --param TEXT Additional parameters for config file in key=value format.
-v, --verbose Increase verbosity of output. [default: 0]
--help Show this message and exit.
Example
The following command runs Krkn-AI with verbose output (-vv), specifies the configuration file (-c), sets the output directory for results (-o), and passes an additional parameter (-p) to override the HOST variable in the config file:
$ uv run krkn_ai run -vv -c ./krkn-ai.yaml -o ./tmp/results/ -p HOST=$HOST
By default, Krkn-AI uses krknctl as engine. You can switch to krknhub by using the following flag:
$ uv run krkn_ai run -r krknhub -c ./krkn-ai.yaml -o ./tmp/results/
4 - Run Krkn-AI (Container)
Use Krkn-AI with a container image.
Krkn-AI can be run inside containers, which simplifies integration with continuous testing workflows.
Container Image
A pre-built container image is available on Quay.io:
podman pull quay.io/krkn-chaos/krkn-ai:latest
Running the Container
The container supports two modes controlled by the MODE environment variable:
1. Discovery Mode
Discovers cluster components and generates a configuration file.
Usage:
# create a folder
mkdir -p ./tmp/container/
# copy kubeconfig to ./tmp/container
# execute discover command
podman run --rm \
--net="host" \
-v ./tmp/container:/mount:Z \
-e MODE="discover" \
-e KUBECONFIG="/mount/kubeconfig.yaml" \
-e OUTPUT_DIR="/mount" \
-e NAMESPACE="robot-shop" \
-e POD_LABEL="service" \
-e NODE_LABEL="kubernetes.io/hostname" \
-e SKIP_POD_NAME="nginx-proxy.*" \
-e VERBOSE="2" \
quay.io/krkn-chaos/krkn-ai:latest
Environment Variables (Discovery):
MODE=discover (required)KUBECONFIG (required) - Path to kubeconfig file (default: /input/kubeconfig)OUTPUT_DIR (optional) - Output directory (default: /output)NAMESPACE (optional) - Namespace pattern (default: .*)POD_LABEL (optional) - Pod label pattern (default: .*)NODE_LABEL (optional) - Node label pattern (default: .*)SKIP_POD_NAME (optional) - Pod names to skip (comma-separated regex)VERBOSE (optional) - Verbosity level 0-2 (default: 0)
2. Run Mode
Executes Krkn-AI tests based on a configuration file.
Usage:
podman run --rm \
--net="host" \
--privileged \
-v ./tmp/container:/mount:Z \
-e MODE=run \
-e CONFIG_FILE="/mount/krkn-ai.yaml" \
-e KUBECONFIG="/mount/kubeconfig.yaml" \
-e OUTPUT_DIR="/mount/result/" \
-e EXTRA_PARAMS="HOST=${HOST}" \
-e VERBOSE=2 \
quay.io/krkn-chaos/krkn-ai:latest
Environment Variables (Run):
MODE=run (required)KUBECONFIG (required) - Path to kubeconfig file (default: /input/kubeconfig)CONFIG_FILE (required) - Path to krkn-ai config file (default: /input/krkn-ai.yaml)OUTPUT_DIR (optional) - Output directory (default: /output)FORMAT (optional) - Output format: json or yaml (default: yaml)EXTRA_PARAMS (optional) - Additional parameters in key=value format (comma-separated)VERBOSE (optional) - Verbosity level 0-2 (default: 0)
Podman Considerations
Container version only supports krknhub runner type at the moment due to limitations around mounting podman socket.
Run without --privileged flag
If you do not want to use the --privileged flag due to security concerns, you can leverage the host’s fuse-overlayfs to run a Podman container.
mkdir -p ./tmp/container/result && chmod 777 ./tmp/container/result
podman run --rm \
--net="host" \
--user podman \
--device=/dev/fuse --security-opt label=disable \
-v ./tmp/container:/mount:Z \
-e MODE=run \
-e CONFIG_FILE="/mount/krkn-ai.yaml" \
-e KUBECONFIG="/mount/kubeconfig.yaml" \
-e OUTPUT_DIR="/mount/result/" \
-e EXTRA_PARAMS="HOST=${HOST}" \
-e VERBOSE=2 \
quay.io/krkn-chaos/krkn-ai:latest
Cache KrknHub images
When running Krkn-AI as a Podman container inside another container with FUSE, you can mount a volume to the container’s shared storage location to enable downloading and caching of KrknHub images.
podman volume create mystorage
mkdir -p ./tmp/container/result && chmod 777 ./tmp/container/result
podman run --rm \
--net="host" \
--user podman \
--device=/dev/fuse --security-opt label=disable \
-v ./tmp/container:/mount:Z \
-v mystorage:/home/podman/.local/share/containers:rw \
-e MODE=run \
-e CONFIG_FILE="/mount/krkn-ai.yaml" \
-e KUBECONFIG="/mount/kubeconfig.yaml" \
-e OUTPUT_DIR="/mount/result/" \
-e EXTRA_PARAMS="HOST=${HOST}" \
-e VERBOSE=2 \
quay.io/krkn-chaos/krkn-ai:latest
5 - Configuration
Configuring Krkn-AI
Krkn-AI is configured using a simple declarative YAML file. This file can be automatically generated using Krkn-AI’s discover feature, which creates a config file from a boilerplate template. The generated config file will have the cluster components pre-populated based on your cluster.
5.1 - Evolutionary Algorithm
Configuring Evolutionary Algorithm
Krkn-AI uses an online learning approach by leveraging an evolutionary algorithm, where an agent runs tests on the actual cluster and gathers feedback by measuring various KPIs for your cluster and application. The algorithm begins by creating random population samples that contain Chaos scenarios. These scenarios are executed on the cluster, feedback is collected, and then the best samples (parents) are selected to undergo crossover and mutation operations to generate the next set of samples (offspring). The algorithm relies on heuristics to guide the exploration and exploitation of scenarios.
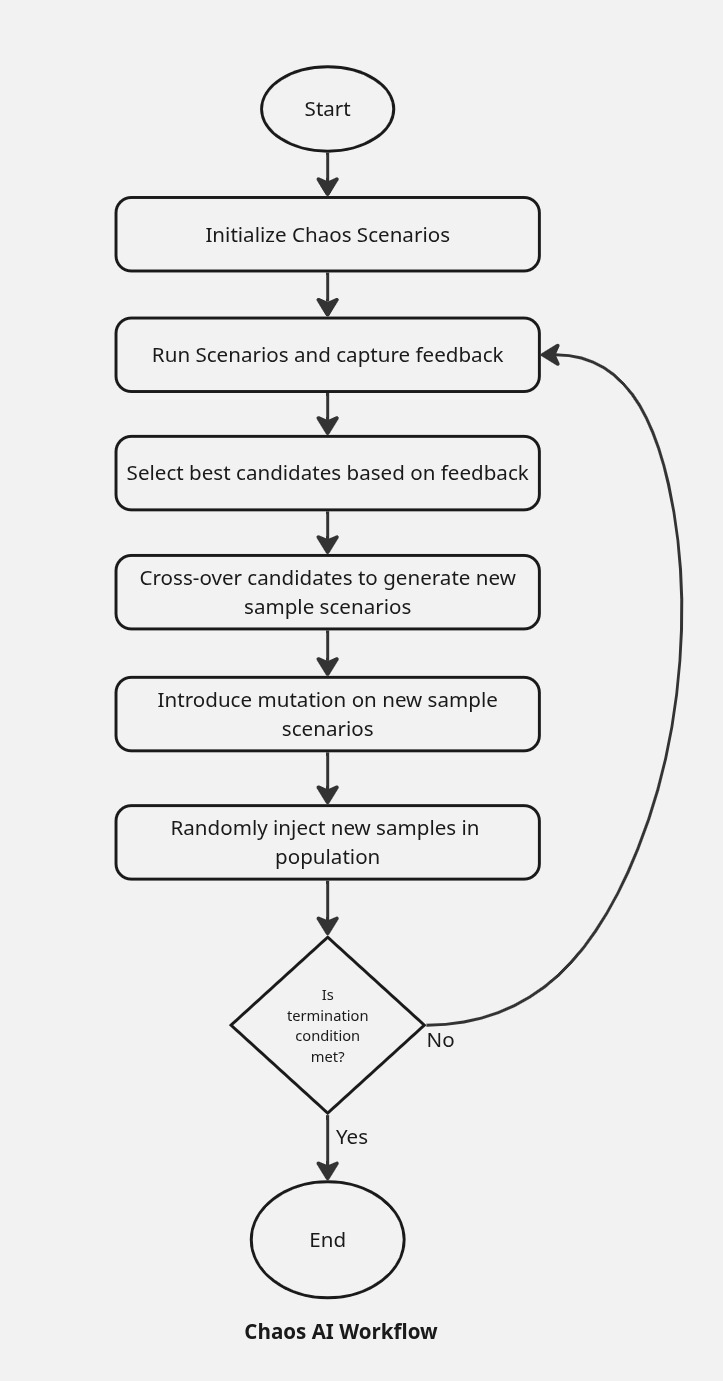
Terminologies
- Generation: A single iteration or cycle of the algorithm during which the population evolves. Each generation produces a new set of candidate solutions.
- Population: The complete set of candidate solutions (individuals) at a given generation.
- Sample (or Individual): A single candidate solution within the population, often represented as a chromosome or genome. In our case, this is equivalent to a Chaos experiment.
- Selection: The process of choosing individuals from the population (based on fitness) to serve as parents for producing the next generation.
- Crossover: The operation of combining two Chaos experiments to produce a new scenario, encouraging the exploration of new solutions.
- Mutation: A random alteration of parts of a Chaos experiment.
- Scenario Mutation: The scenario itself is changed to a different one, introducing greater diversity in scenario execution while retaining the existing run properties.
- Composition: The process of combining existing Chaos experiments into a grouped scenario to represent a single new scenario.
- Population Injection: The introduction of new individuals into the population to escape stagnation.
Configurations
The algorithm relies on specific configurations to guide its execution. These settings can be adjusted in the Krkn-AI config file, which you generate using the discover command.
generations
Total number of generation loop to run (Default: 20)
- The value for this field should be at least 1.
- Setting this to a higher value increases Krkn-AI testing coverage.
- Each scenario tested in the current generation retains some properties from the previous generation.
population_size
Minimum Population size in each generation (Default: 10)
- The value for this field should be at least 2.
- Setting this to a higher value will increase the number of scenarios tested per generation, which is helpful for running diverse test samples.
- A higher value is also preferred when you have a large set of objects in cluster components and multiple scenarios enabled.
- If you have a limited set of components to be evaluated, you can set a smaller population size and fewer generations.
crossover_rate
How often crossover should occur for each scenario parameter (Default: 0.6 and Range: [0.0, 1.0])
- A higher crossover rate increases the likelihood that a crossover operation will create two new candidate solutions from two existing candidates.
- Setting the crossover rate to
1.0 ensures that crossover always occurs during selection process.
mutation_rate
How often mutation should occur for each scenario parameter (Default: 0.7 and Range: [0.0, 1.0])
- This helps to control the diversification among the candidates. A higher value increases the likelihood that a mutation operation will be applied.
- Setting this to
1.0 ensures persistent mutation during the selection process.
scenario_mutation_rate
How often a mutation should result in a change to the scenario (Default: 0.6; Range: [0.0, 1.0])
- A higher rate increases diversity between scenarios in each generation.
- A lower rate gives priority to retaining the existing scenario across generations.
composition_rate
How often a crossover would lead to composition (Default: 0.0 and Range: [0.0, 1.0])
- By default, this value is disabled, but you can set it to a higher rate to increase the likelihood of composition.
population_injection_rate
How often a random samples gets newly added to population (Default: 0.0 and Range: [0.0, 1.0])
- A higher injection rate increases the likelihood of introducing new candidates into the existing generation.
population_injection_size
What’s the size of random samples that gets added to new population (Default: 2)
- A higher injection size means that more diversified samples get added during the evolutionary algorithm loop.
- This is beneficial if you want to start with a smaller population test set and then increase the population size as you progress through the test.
wait_duration
Time to wait after scenario execution. Sets Krkn’s --wait-duration parameter. (Default: 120 seconds)
stopping_criteria
Configuration for advanced stopping conditions based on fitness, saturation, or exploration limits. See Stopping Criteria for full details.
5.2 - Fitness Function
Configuring Fitness Function
The fitness function is a crucial element in the Krkn-AI algorithm. It evaluates each Chaos experiment and generates a score. These scores are then used during the selection phase of the algorithm to identify the best candidate solutions in each generation.
- The fitness function can be defined as an SLO or as cluster metrics using a Prometheus query.
- Fitness scores are calculated for the time range during which the Chaos scenario is executed.
Example
Let’s look at a simple fitness function that calculates the total number of restarts in a namespace:
fitness_function:
query: 'sum(kube_pod_container_status_restarts_total{namespace="robot-shop"})'
type: point
This fitness function calculates the number of restarts that occurred during the test in the specified namespace. The resulting value is referred to as the Fitness Function Score. These scores are computed for each scenario in every generation and can be found in the scenario YAML configuration within the results. Below is an example of a scenario YAML configuration:
generation_id: 0
scenario_id: 1
scenario:
name: node-memory-hog(60, 89, 8, kubernetes.io/hostname=node1,
[], 1, quay.io/krkn-chaos/krkn-hog)
cmd: 'krknctl run node-memory-hog --telemetry-prometheus-backup False --wait-duration
0 --kubeconfig ./tmp/kubeconfig.yaml --chaos-duration "60" --memory-consumption
"89%" --memory-workers "8" --node-selector "kubernetes.io/hostname=node1"
--taints "[]" --number-of-nodes "1" --image "quay.io/krkn-chaos/krkn-hog" '
log: ./results/logs/scenario_1.log
returncode: 0
start_time: '2025-09-01T16:55:12.607656'
end_time: '2025-09-01T16:58:35.204787'
fitness_result:
scores: []
fitness_score: 2
job_id: 1
health_check_results: {}
In the above result, the fitness score of 2 indicates that two restarts were observed in the namespace while running the node-memory-hog scenario. The algorithm uses this score as feedback to prioritize this scenario for further testing.
Types of Fitness Function
There are two types of fitness functions available in Krkn-AI: point and range.
Point-Based Fitness Function
In the point-based fitness function type, we calculate the difference in the fitness function value between the end and the beginning of the Chaos experiment. This difference signifies the change that occurred during the experiment phase, allowing us to capture the delta. This approach is especially useful for Prometheus metrics that are counters and only increase, as the difference helps us determine the actual change during the experiment.
E.g SLO: Pod Restarts across “robot-shop” namespace.
fitness_function:
query: 'sum(kube_pod_container_status_restarts_total{namespace="robot-shop"})'
type: point
Range-Based Fitness Function
Certain SLOs require us to consider changes that occur over a period of time by using aggregate values such as min, max, or average. For these types of value-based metrics in Prometheus, the range type of Fitness Function is useful.
Because the range type is calculated over a time interval—and the exact timing of each Chaos experiment may not be known in advance—we provide a $range$ parameter that must be used in the fitness function definition.
E.g SLO: Max CPU observed for a container.
fitness_function:
query: 'max_over_time(container_cpu_usage_seconds_total{namespace="robot-shop", container="mysql"}[$range$])'
type: range
Defining Multiple Fitness Functions
Krkn-AI allows you to define multiple fitness function items in the YAML configuration, enabling you to track how individual fitness values vary for different scenarios in the final outcome.
You can assign a weight to each fitness function to specify how its value impacts the final score used during Genetic Algorithm selection. Each weight should be between 0 and 1. By default, if no weight is specified, it will be considered as 1.
fitness_function:
items:
- query: 'sum(kube_pod_container_status_restarts_total{namespace="robot-shop"})'
type: point
weight: 0.3
- query: 'sum(kube_pod_container_status_restarts_total{namespace="etcd"})'
type: point
Krkn Failures
Krkn-AI uses krknctl under the hood to trigger Chaos testing experiments on the cluster. As part of the CLI, it captures various feedback and returns a non-zero status code (exit status 2) when a failure occurs. By default, feedback from these failures is included in the Krkn-AI Fitness Score calculation.
You can disable this by setting the include_krkn_failure to false.
fitness_function:
include_krkn_failure: false
query: 'sum(kube_pod_container_status_restarts_total{namespace="robot-shop"})'
type: point
Note: If a Krkn scenario exits with a non-zero status code other than 2, Krkn-AI assigns a fitness score of -1 and stops the calculation of health scores. This typically indicates a misconfiguration or another issue with the scenario. For more details, please refer to the Krkn logs for the scenario.
Health Check
Results from application health checks are also incorporated into the fitness score. You can learn more about health checks and how to configure them in more detail here.
How to Define a Good Fitness Function
Scoring: The higher the fitness score, the more priority will be given to that scenario for generating new sets of scenarios. This also means that scenarios with higher fitness scores are more likely to have an impact on the cluster and should be further investigated.
Normalization: Krkn-AI currently does not apply any normalization, except when a fitness function is assigned with weights. While this does not significantly impact the algorithm, from a user interpretation standpoint, it is beneficial to use normalized SLO queries in PromQL. For example, instead of using the maximum CPU for a pod as a fitness function, it may be more convenient to use the CPU percentage of a pod.
Use-Case Driven: The fitness function query should be defined based on your use case. If you want to optimize your cluster for maximum uptime, a good fitness function could be to capture restart counts or the number of unavailable pods. Similarly, if you are interested in optimizing your cluster to ensure no downtime due to resource constraints, a good fitness function would be to measure the maximum CPU or memory percentage.
5.3 - Stopping Criteria
Configuring Stopping Criteria for the Genetic Algorithm
The stopping criteria framework lets users define when the genetic algorithm should terminate, allowing for more flexible control beyond strictly generation count or time limits. By configuring these parameters, you can ensure the algorithm stops once it achieves a target fitness or if it reaches a state of saturation where no further improvements or discoveries are being made.
Configurations
You can configure the following options under the stopping_criteria section of the Krkn-AI config file. All fields are optional and, with the exception of saturation_threshold, default to disabled (null).
fitness_threshold
- Description: Stops the algorithm when the best fitness score reaches or exceeds this specific value.
- Default: Disabled (
null)
This is useful when you have a specific target fitness score (e.g., an SLO violation count) that, once reached, indicates the objective has been met.
generation_saturation
- Description: Stops the algorithm if there is no significant improvement in the best fitness score for N consecutive generations.
- Default: Disabled (
null)
This helps prevent the algorithm from running needlessly after it has converged to a solution.
exploration_saturation
- Description: Stops the algorithm if no new unique scenarios (test cases) are discovered for N consecutive generations.
- Default: Disabled (
null)
This indicates that the algorithm has likely exhausted its search space given the current configuration and is engaging in redundant exploration.
saturation_threshold
- Description: Configures the minimum fitness improvement required to consider a fitness change as “significant” for the purpose of resetting the saturation counter.
- Default:
0.0001
If the improvement in fitness is less than this threshold, it is treated as stagnation.
Example Configuration
stopping_criteria:
fitness_threshold: 200 # stop when fitness >= 200
generation_saturation: 5 # stop if no improvement for 5 generations
exploration_saturation: 3 # stop if no new scenarios for 3 generations
saturation_threshold: 0.0001 # minimum improvement to reset saturation counter
5.4 - Application Health Checks
Configuring Application Health Checks
When defining the Chaos Config, you can provide details about your application endpoints. Krkn-AI can access these endpoints during the Chaos experiment to evaluate how the application’s uptime is impacted.
Note
Application endpoints must be accessible from the system where Krkn-AI is running in order to reach the service.Configuration
The following configuration options are available when defining an application for health checks:
- name: Name of the service.
- url: Service endpoint; supports parameterization with “$”.
- status_code: Expected status code returned when accessing the service.
- timeout: Timeout period after which the request is canceled.
- interval: How often to check the endpoint.
- stop_watcher_on_failure: This setting allows you to stop the health check watcher for an endpoint after it encounters a failure.
Example
health_checks:
stop_watcher_on_failure: false
applications:
- name: cart
url: "$HOST/cart/add/1/Watson/1"
status_code: 200
timeout: 10
interval: 2
- name: catalogue
url: "$HOST/catalogue/categories"
- name: shipping
url: "$HOST/shipping/codes"
- name: payment
url: "$HOST/payment/health"
- name: user
url: "$HOST/user/uniqueid"
- name: ratings
url: "$HOST/ratings/api/fetch/Watson"
URL Parameterization
When defining Krkn-AI config files, the URL entry for an application may vary depending on the cluster. To make the URL configuration more manageable, you can specify the values for these parameters at runtime using the --param flag.
In the previous example, the $HOST variable in the config can be dynamically replaced during the Krkn-AI experiment run, as shown below.
uv run krkn_ai run -c krkn-ai.yaml -o results/ -p HOST=http://example.cluster.url/nginx
By default, the results of health checks—including whether each check succeeded and the response times—are incorporated into the overall Fitness Function score. This allows Krkn-AI to use application health as part of its evaluation criteria.
If you want to exclude health check results from influencing the fitness score, you can set the include_health_check_failure and include_health_check_response_time fields to false in your configuration.
fitness_function:
...
include_health_check_failure: false
include_health_check_response_time: false
5.5 - Scenarios
Available Kkrn-AI Scenarios
The following Krkn scenarios are currently supported by Kkrn-AI.
At least one scenario must be enabled for the Kkrn-AI experiment to run.
By default, scenarios are not enabled. Depending on your use case, you can enable or disable these scenarios in the krkn-ai.yaml config file by setting the enable field to true or false.
scenario:
pod-scenarios:
enable: true
application-outages:
enable: false
container-scenarios:
enable: false
node-cpu-hog:
enable: true
node-memory-hog:
enable: true
node-io-hog:
enable: false
syn-flood:
enable: false
time-scenarios:
enable: true
network-scenarios:
enable: false
dns-outage:
enable: true
pvc-scenarios:
enable: false
5.6 - Output
Configuring output formatters
Krkn-AI generates various output files during the execution of chaos experiments, including scenario YAML files, graph visualizations, and log files. By default, these files follow a standard naming convention, but you can customize the file names using format strings in the configuration file.
Available Parameters
The output section in your krkn-ai.yaml configuration file allows you to customize the naming format for different output file types:
result_name_fmt
Specifies the naming format for scenario result YAML files. These files contain the complete scenario configuration and execution results for each generated scenario.
Default: "scenario_%s.yaml"
graph_name_fmt
Specifies the naming format for graph visualization files. These files contain visual representations of the health check latency and success information.
Default: "scenario_%s.png"
log_name_fmt
Specifies the naming format for log files. These files contain execution logs for each scenario run.
Default: "scenario_%s.log"
The format strings support the following placeholders:
%g - Generation number%s - Scenario ID%c - Scenario Name (e.g pod_scenarios)
Example
Here’s an example configuration that customizes all output file names:
output:
result_name_fmt: "gen_%g_scenario_%s_%c.yaml"
graph_name_fmt: "gen_%g_scenario_%s_%c.png"
log_name_fmt: "gen_%g_scenario_%s_%c.log"
With this configuration, files will be named like:
gen_0_scenario_1_pod_scenarios.yamlgen_0_scenario_1_pod_scenarios.pnggen_0_scenario_1_pod_scenarios.log
5.7 - Elastic Search
Configuring Elasticsearch for Krkn-AI results storage
Krkn-AI supports integration with Elasticsearch to store scenario configurations, run results, and metrics. This allows you to centralize and query experiment data using Elasticsearch’s search and visualization capabilities (e.g., with Kibana).
Configuration Parameters
enable (bool): Set to true to enable saving results to Elasticsearch. Default: false.server (string): URL or address of your Elasticsearch server (e.g., http://localhost).port (int): Port to connect to Elasticsearch (default: 9200).username (string): Username for Elasticsearch authentication (can reference environment variables).password (string): Password for Elasticsearch authentication. If using environment substitution, prefix with __ to treat as private.verify_certs (bool): Set to true to verify SSL certificates. Default: true.index (string): Name prefix for the Elasticsearch index where Krkn-AI results will be stored (e.g., krkn-ai).
Example Configuration
elastic:
enable: true # Enable Elasticsearch integration
server: "http://localhost" # Elasticsearch server URL
port: 9200 # Elasticsearch port
username: "$ES_USER" # Username (environment substitution supported)
password: "$__ES_PASSWORD" # Password (start with __ for sensitive/private handling)
verify_certs: true # Verify SSL certificates
index: "krkn-ai" # Index prefix for storing results
In addition to the standard Krkn telemetry and metrics indices, Krkn-AI creates two dedicated Elasticsearch indices to store detailed run information:
krkn-ai-config: Stores comprehensive information about the Krkn-AI configuration for each run, including parameters for the genetic algorithm, enabled scenarios, SLO definitions, and other configuration details.krkn-ai-results: Stores the results of each Krkn-AI run, such as fitness scores, health check evaluations, and related metrics.
Note: Depending on the complexity and number of scenarios executed, Krkn-AI can generate a significant amount of metrics and data per run. Ensure that your Elasticsearch deployment is sized appropriately to handle this volume.